Vercelでブログを公開した
https://noy72.com/
作成したサイト.
https://noy72.com/articles/2021-02-01-vercel/
ブログを作成したことについて書いた記事.
今後はnoy72.comで記事を書いていく予定.
はてなブログにある記事は,リンクされているものはそのままで,それ以外はnoy72.comに移動させていく.
Pool.imap で引数の関数が実行されるタイミングについてメモ [Python]
Generator を使ったコードを以下に示す.
def get_time(x=None): sleep(1) return datetime.now().time() def generator(): while True: yield get_time() if __name__ == '__main__': it = generator() sleep(5) print(datetime.now().time(), 'Begin') print(next(it)) print(next(it)) print(next(it)) print(datetime.now().time(), 'End')
上記のコードの実行結果は以下のようになる.
12:01:04.985315 Begin 12:01:05.986125 12:01:06.989681 12:01:07.993368 12:01:07.993416 End
get_timeは,呼ぶと1秒待ってから現在時刻を返す.
next(it)によってget_timeが呼ばれるため,約1秒毎に現在時刻を返す.
Pool.imap を使ったコードを以下に示す.
ここで呼ばれているget_timeは上記のコードと同様である.
if __name__ == '__main__': with Pool(processes=2) as p: it = p.imap(get_time, [1, 2, 3]) sleep(5) print(datetime.now().time(), 'Begin') print(next(it)) print(next(it)) print(next(it)) print(datetime.now().time(), 'End')
実行結果は以下のようになる.
12:01:13.042683 Begin 12:01:09.043455 12:01:09.043456 12:01:10.044876 12:01:13.043180 End
next(it)が呼ばれているのはprint(datetime.now().time(), 'Begin')の後だが,出力された時刻はBeginの時点より早い.
Generator を使ったコードでは,next(it)を呼び出した時点でget_timeが呼び出される.
一方で,Pool.imap を使ったコードでは,Pool.imap を実行した時点で get_time が実行され始める.
sleep(5) で待機している間に,get_time の三度の呼び出しが非同期で実行され,結果が保持される.
その後の next(it) では,すでに実行した get_time の結果を返すだけで,get_time の実行はされない.
『Atomic Design堅牢で使いやすいUIを効率良く設計する』を読んだ
非職業プログラマがAtomic Designを読んだ感想.
背景
ReactのチュートリアルをやったりDocsを読んだりしたけど,どうやってUIを作るのかがイマイチわからない.デザインモックからUIを実装する例がここにあるが,もう少し詳細な説明が欲しいところ.UIを分割して階層構造を持たせるのはわかるけど…… しかも,世間では関数コンポーネントを使ってUIを構築したりするそう.クラスコンポーネントしかしらないよ!.
そこでとりあえず読んだのがAtomic Design.結論から言うと読んで良かった.
Atomic Designとはなんぞや
Atomic Design は小さいUIコンポーネントを組み合わせてより大きなコンポーネントを作っていくためのデザイン・フレームワークです.(p.66)
UIコンポーネントを粒度(抽象度)ごとに分類して,それらを組み合わせてコンポーネントやアプリケーションを作る方法.React公式の例ではUIコンポーネントが木構造になっているようなイメージで,Atomic Designの方はDAG(有向無閉路グラフ)になっているイメージ.
分類は,小さい方からAtoms, Molecules, Organisms, Templates, Pageと分かれている.分類をする際は,コンポーネントがどんな責務を負っているのか(どんなことに関心があるのか)に注目する.例えば,Templatesに分類されたコンポーネントは,「何を表示するか」ではなく,「画面全体のレイアウト」にだけ関心を持つ.各コンポーネントが1つの責務だけ持つことで,それだけに集中して開発ができる.
この分類でなくともよい
原著のこのあたりで,以下のように述べている.
Ultimately, whatever taxonomy you choose to work with should help you and your organization communicate more effectively in order to craft an amazing UI design system.
Atomic Designに限った話ではないけど,どんな手法を使うかは大事ではなくて,決められた手法に従うことでより効果的にコミュニケーションが取れるかどうかが大事.必要の応じて分類法を減らしたり増やしたりして使いやすいようにアレンジしてもよい.
読んだ感想
Storybookが便利
UIコンポーネントの作成で困ったのが,期待通りに表示されているかを確認するのが面倒ということ.本書ではStorybookというUIコンポーネント開発環境を使っている.
Storybookは作成したコンポーネントを個別に表示できる.そのため,コンポーネント作成→Storybookで確認→間違いを修正→確認→……と開発を進めることができる.ユニットテストの元で関数を実装しているのと同様の気持ちで開発が進められる.
1つのコンポーネントに1つの責務という考え
本書では,コンポーネントが複数の責務を持たないようにコードを小さく分割している.このような,「このコンポーネント(関数,クラス)は何に責務を負っているか」に注目して実装を分割するのは,『Clean Code』にもあるように,UIコンポーネントの開発に限った話ではない.サンプルコードを追うことで,「責務に注目する」というコードを書く上での基礎となる部分の練習ができる.
手を動かせるようになる
小さいものをはじめに作り,それを組み合わせて徐々に大きいものを作ることを体験できる.UIコンポーネントはどこから手をつけていけばいいのかわからなかったけど,手が動かせるようになったので,個人的にはよかった.
ただ,開発の方法を学んだだけなので,実際に作るのはやっぱり難しい.Storybookを見てはCSSを書き直し,見ては書き直し……を繰り返している.
レイアウトはAtoms ? Templates?
Atomsに分類されるものの例として,テキストやボタン,レイアウト・パターンを挙げている.前2つはいいとして,Atomsにレイアウト・パターンが入るのはなぜなのか? Templatesじゃない?
Atomic Design の大きな特徴の1つは,Atoms,Molecules,Organisms,と化学用語が続いた後で,Templates,Pages と通常の開発用語が登場することです.ここには,「開発者だけで使う用語」と「開発者以外に対しても使う用語」という区別が表現されています.(p.68)
レイアウトは,特定のコンテンツに依存しない機能なので,Atoms 層のコンポーネントとして作成するといいでしょう.(p.77)
Templates 層はその名の通りページの雛形です.(中略)Templates 層のコンポーネントに実際のコンテンツを流し込んだものが Pages です.(p.90)
Atomsにあるレイアウト・パターンもTemplatesも,何らかのレイアウトを決めるという点では両方同じ.ただし,TemplatesはPagesのレイアウトを決めるもので,Atomsのレイアウト・パターンはMoleculesやOrganismsのレイアウトを決めるものという気がする.別の言い方をすると,Templatesはユーザーとって必要な情報が適切な場所に置かれているかに関心を持ち,Atomsのレイアウト・パターンは単にコンポーネントが想定された通りに配置されているかに関心を持つんじゃないかと思う.
関連サイト
atomicdesign.bradfrost.com 原著のサイト.
bradfrost.com 原著の著者のブログ.Atomic designの拡張について.
Atomic designに関する記事
tech.ga-tech.co.jp Atomic Designをやめた事例.コンポーネントの分類にコストがかかってしまうこと,プロダクトの性質によってはAtomic Designの運用がうまくいかないことを書いている.
tech.connehito.com Atomic designでハマったポイントとかを書いている.
『Clean Coder プロフェッショナルプログラマへの道』を読んだ
Clean なんとかシリーズ.
asciidwango.jp前に読んだのは Clean Architecture ↓ noy.hatenablog.jp
本書の内容
プログラマとしての考え方や振る舞いについてと技術的な内容も少し. 本書の半分ぐらいを大雑把にまとめると,周りの人たちとどのようなコミュニケーションをとるか,という内容. 第2章 『「ノー」と言う』,第3章 『「イエス」と言う』が特に印象的だった. 「スケジュールに合わせてやってください」「できません」「でもやってください」「できません」「ではよろしく」みたいな会話がどこかでされているかと思うと辛い気持ちになる.
「プロ」とは何か
- マイクロマネジメントされない
- 敬意をもって接される・蔑ろにされない
意見を全く聞き入れてもらえないとき,プロ扱いされていない.
プロの行動とは何か
コードが動作することを把握する
コードが動いていることを把握するためにはテストをすればよい.カバレッジを 100% にしたほうがいいではなく,そうしろ(可能な限りカバレッジを高めろ)と主張する.テストとリファクタリングの組み合わせが重要であるというのはいろんな書籍に出てくるけど,「カバレッジ 100%! それ以外にあるか!?」みたいなのは見たことがなかった.
また,TDDを強く推奨している.TDDの利点の一つとして,テスト可能な設計を強制されるという点が挙げられている.「テストを先に書く」というと単に順序を入れ替えただけに聞こえるけど,実際はそんな単純ではない上,TDDによって作成されたテストは十分ではない.本書では以下のように書かれている.
以上のように優れた点はあるが,TDDは宗教や魔法の手法ではない.
「イエス」というべきか「ノー」というべきか
答えは,二人(あるいはそれ以上)が目標を合わせるためには,
- 何がいつまでにできて,
- 何がいつまでにはできなくて,
- 何がいつ必要になるのか
をはっきりさせなければならない.
「〇〇までに△△が必要」という状況において,
〇〇がその日までにできるのであれば「イエス」と答えられる.できないのに「やってみます」はかなりまずい.
「〇〇までに△△が必要って言ったじゃないか!」
「ええ,ですから申し上げた通りやってみましたよ.その結果できませんでしたが」
できないものは「ノー」とはっきり言う必要がある.
「〇〇までに△△ですか? 無理です.以上(もう話しかけないでね)」
ただ,「ノー」を言うだけではいけない.
何ができて,何ができないのか,そして何が必要になっているかを明らかにしなければならない.場合によっては優先順位や予定,(どうしても無理なら)必要とされているものを変更したり,計画的に残業をするなど,別の方法を取る必要がある.プロは「イエス」と言えるような創造的な方法を探さなければならない.
(多分,テストを後回しにしたり,長期間残業するのは創造的じゃない)
緊急対応
メネージャが期限に間に合わせるように言ってきたらどうするだろうか? マネージャが「コレお願い!」と言ってきたらどうするだろうか? 自分の見積もりを死守するのだ! (p.86)
死守できるほど信じれる見積もりを持たなければ……
コーディング
音楽を聴きながら作業しない
これに関連する研究がいくつかあると聞いたことがある.調べていないので真実かはわからないが,
- 基本的には無音,あるいは自然音が良い.
- 新しいアイデアを考えたりするような想像的な作業をするときは,ざわつきが聞こえた方が良い(カフェとか).
- 歌詞のある曲(理解できる言語)を聴きながら作業すると生産性が落ちる.
- 生産性は上がるような音楽はあるが(ゆったりした曲だったかな?),内向的な人には効果が薄い.
- 作業をする前に音楽を聴いて気分を上げると,のちの作業が捗る.ただし,作業中は音楽を聞いてはいけない.
みたいな噂がある.(TODO:ソースの追加)
ステレオをかけながらコードを書いたものだ.(中略)コードのコメントには,曲の歌詞と爆撃機や泣き叫ぶ赤ん坊のことが書かれていた.(p.80)
まぁ,聴いている曲の歌詞をコメントに残しちゃう人なら間違いなく聞かないほうが良いとは思う.
フロー(ゾーン)について
1人の時間が不要というわけではない.もちろんそれは必要だ.(中略)例えば,10時から12時までは話しかけないでほしいと周知しておき,13時から15時まではドアを開けたままにしておくといった具合だ.(p.88)
あらかじめ時間を決めておくことで割り込みを制御する,という手法を認めつつも,
問題は,ゾーンに入ると大局観を失ってしまうことだ.(p.79)
ペアプログラミングの大きな利点は,ペアでゾーンに入るのは事実上不可能なことにある.(p,79)
ワークステーションでコードを書いているときの自分を思い浮かべてみよう.(中略)感じの悪い反応はゾーンと関係していることが多い.(中略)ただし,悪いのはゾーンではなく,集中力が必要なことを1人で理解しようとすることだ.(p.80~81)
ここでいう「ゾーン」は「フロー」と同じような意味で,深い集中状態に入っていることを示す.
上記のように,「ゾーン」を意図的に避けることを提案しており,ペアで作業をすることをそこそこ推奨している.(ペアプログラミングをしよう! という直接的な推奨は本書ではされていない).
『フロー体験 喜びの現象学』では「フロー」を良いものとして扱っており,噂ではちょっとした割り込みで集中状態が解かれ,もとの集中している状態に戻るのには10分以上もかかるという(TODO:ソースの追加).だから,「フロー」に入る・維持することは重要だと思っていたけど,それ以外の考えもあるらしい.
割り込みへの対処法として,あらかじめ「何で割り込まれそうか」「割り込まれた際の行動をどうするか」を考えておくというものがある(TODO:ソースの追加).
まとめ
- コードが動くことに責任を持つ
- どうしても無理なら「ノー」というが,「イエス」をいえるような手法を探す
- テスト大事
- 割り込みを対処できるようにしておく
Lisp 布教書 『Land of Lisp』を読んだ
ここが原著の公式サイト.
以下の書籍が実際に読んだ翻訳版. www.oreilly.co.jp
Land of Lisp に載っていること
- クロマニヨン人について
- 副作用を利用したことで Haskell 共和国に身柄を拘束されることとなった少年(フィクション)
- サスカッチなどと言われていた未確認生物が,Lisperであるかもしれないということ
(MIT の地下にいるかも) - 楽しい漫画!
- こんなヤバいプログラム,教科書に載っていいのか!(原文ママ)
- ジェーン・オースティンはズッ友よ!(原文ママ)
もうちょっと真面目に
本書の内容は,簡単なゲームの開発などを通して Lisp の文法や機能を解説するというもの.ゲーム開発では隣接リストを用いたグラフ表現が出てきたりする.ゲーム以外だと,Web サーバーを立てたり,DSL を作成したりする(ゲーム開発の一貫だけど).
原文でどう書かれているかは分からないが,訳された文章は軽快で,教科書や技術書というよりも布教書と言いたくなる.
実際に読んでみて
Lispというとカッコだらけの難解な言語,というイメージだった.なにせマスコットは Lisp エイリアン.実際に (Common)Lisp に触れてみると,Lisp は意味不明の謎言語というわけではないことがわかった.
というのも,関数呼び出しなら,
add(2, 5) // いつもの関数呼び出し
(add 2 5) ; カッコ '(' が関数名の右に移動した
値の演算なら,
1 + 2 * 3 // いつもの演算
(+ 1 (* 2 3)) ; add(1, mul(2, 3)) みたいな順序
と,割と自然に解釈できるからだ.
Lisp のおかげか別の言語でラムダ式や高階関数を触ったおかげかはわからないが,前に Haskell を勉強したときに比べてはるかに理解しやすかった.読み進めると Lisp にも慣れてきて,心なしか Lisp エイリアンも可愛く見えて……はこなかった. 目が多いのすかんそす……
カッコが多い ))))
カッコが連続するせいでどれが対応しているかがわかりにくい.これはむしろ,カッコだらけでわからなくなるような大きな関数を作るなという示唆かもしれない.実際,本書に乗っているコードの関数はどれも小さい.小さな部品を組み合わせて期待する機能を実現しており,手続き的に書くのとは全く違うことがわかる.
発見
- Common Lisp は意外にも手続き的に書ける.
- 文法はそんなに変じゃない(気がする).
def hello(): print("Hello World")
(defun hello() (princ "Hello World"))
そもそも Hello World ほど小さいコードなら,どの言語も差が小さくなるから比較しても意味がないよね.
let を使ったり,リストの操作をしたりするともっとカッコだらけになる.
まとめ
次は Haskell を学び直そう.
Ajax通信をする小さなアプリの作成[JavaScript Primer]
JavaScript Primer - 迷わないための入門書 #jsprimerのAjax通信 · JavaScript Primer #jsprimerを実際にやって見た際のメモ.
作るもの
環境
- macOS catalina
- Node.js v13.13.0
真っ白のページを作る
まず,サーバーを立てて,HTMLにアクセスできる状態にします.
プロジェクトディレクトリの作成
今回はAjax-sampleというディレクトリを作成し,そのディレクトリ以下で作業をします.
HTMLファイルの作成
エントリーポイントとなるhtmlファイルを作成します.index.jsを読み込むだけの真っ白なページです.
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Ajax Sample</title> </head> <body> <script src="index.js"></script> </body> </html>
JavaScriptファイルの作成
読み込めているかを確認するだけなので,適当な文字列を表示するコードを書きます.
console.log("OK");
サーバーを立てる
Node.jsを使ってサーバーを立てます.Express.jsを使ってもいいですが,今回はhttp.createServerを使って素朴に実装します.
一部のIDEは特別な設定をしなくてもhtmlをローカルサーバー上で見られるので,この部分は省略できます.
実装
Server.js
const http = require('http'); const fs = require('fs'); const contentType = new Map([ ["html", "text/html"], ["js", "text/javascript"], ["css", "text/css"], ["png", "image/png"], ["ico", "image/vnd.microsoft.icon"], ]); http.createServer(function (req, res) { const ext = req.url.split('.').pop(); try { const data = fs.readFileSync('.' + req.url); res.writeHead(200, {'Content-Type': contentType.get(ext)}); res.write(data); } catch (e) { res.writeHead(404, {'Content-Type': 'text/plain'}); res.write(e.message); } res.end(); }).listen(8080);
http.createServer
req.urlで指定されたファイルを返します.指定されたファイルが存在しない時,エラーメッセージを返します.
http.createServer(function (req, res) { const ext = req.url.split('.').pop(); try { const data = fs.readFileSync('.' + req.url); res.writeHead(200, {'Content-Type': contentType.get(ext)}); res.write(data); } catch (e) { res.writeHead(404, {'Content-Type': 'text/plain'}); res.write(e.message); } res.end(); }).listen(8080);
参考:Node.js http.createServer() Method
contentType
[拡張子, contentType]のMap.リクエストされたファイルの拡張子によって,適切なContentTypeを返します.
const contentType = new Map([ ["html", "text/html"], ["js", "text/javascript"], ["css", "text/css"], ["png", "image/png"], ["ico", "image/vnd.microsoft.icon"], ]);
HTMLの表示
Ajax-sample ├── index.html ├── index.js └── server.js
Ajax-sample下でnode server.jsを実行し,http://localhost:8080/index.htmlにアクセスすると,以下のようなページが表示されます.コンソールには"OK"が表示されます.ファビコンは用意していないので404が返ります.
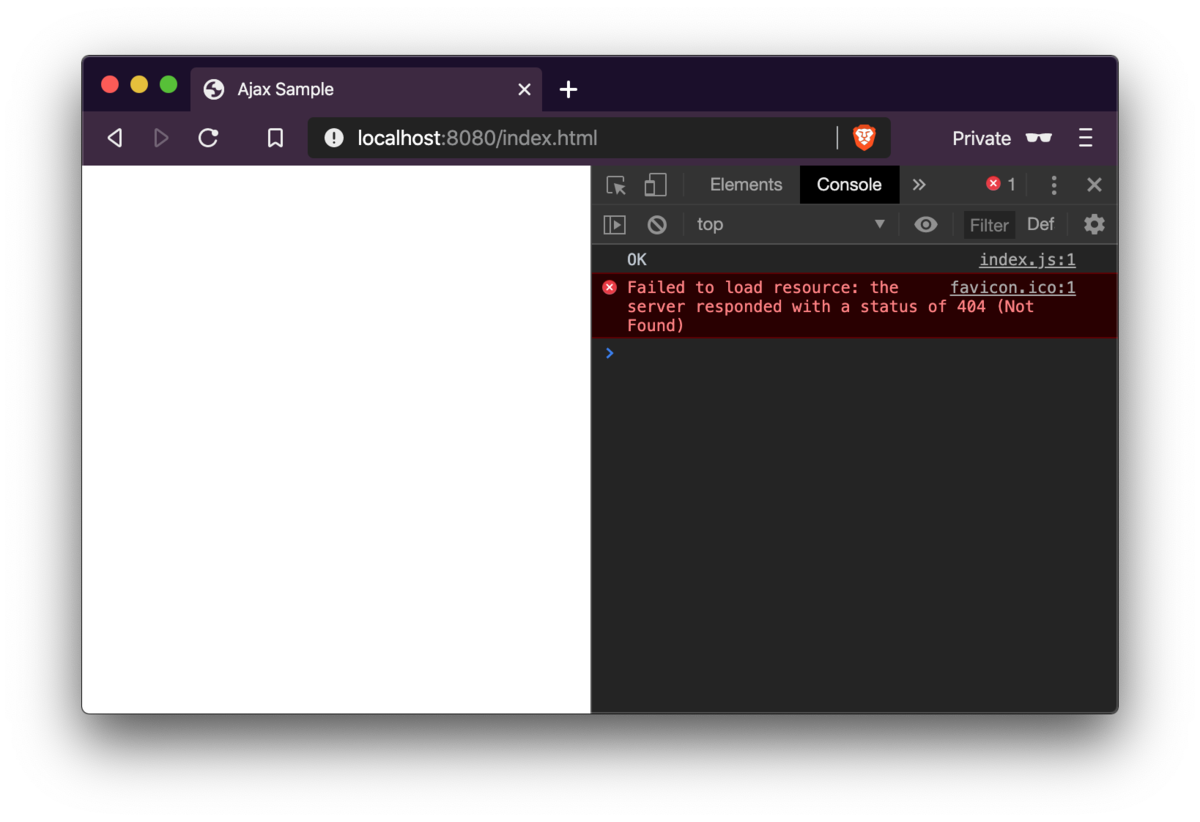
今回の実装ではhttp://localhost:8080以下の文字列をファイル名として処理するので,http://localhost:8080やhttp://localhost:8080/indexではファイルが読み込めません.
HTTP通信
次に,API(Users - GitHub Docs)を呼び出して,レスポンスをコンソールに表示します.
HTTPリクエストを送る関数の作成
fetchメソッドでHTTPリクエストを作成,送信ができます.このメソッドはPromiseを返すため,thenで成功時と失敗時に呼ばれる関数を登録します.また,レスポンスのデータをjsonに変換するメソッドもPromiseを返すので,jsonをコンソールに表示する関数を渡しておきます.
特定の文字がURIに含まれていると正しく動作しないため,encodeURIComponent()でエスケープしておきます.
function fetchUserInfo(userId) { fetch(`https://api.github.com/users/${encodeURIComponent(userId)}`).then( (response) => { if (response.ok) { return response.json().then(userInfo => console.log(userInfo)); } else { console.log("Error :", response); } }, (error) => { console.log(error); } ); }
参考:encodeURIComponent() - JavaScript | MDN
HTTPリクエストを送るためのボタンを作成
HTMLにボタンを作成し,そのボタンを押すとfetchUserInfoを呼び出すようにします.ここでは,userIdを埋め込んでいます.
... <body> <button onclick="fetchUserInfo('noy72');">Get user info</button> <script src="index.js"></script> </body> ...
実際に送ってみる
http://localhost:8080/index.htmlにアクセスし,表示されているボタンを押すと,HTTPリクエストが送られます.結果は以下のようにコンソールに表示されます.
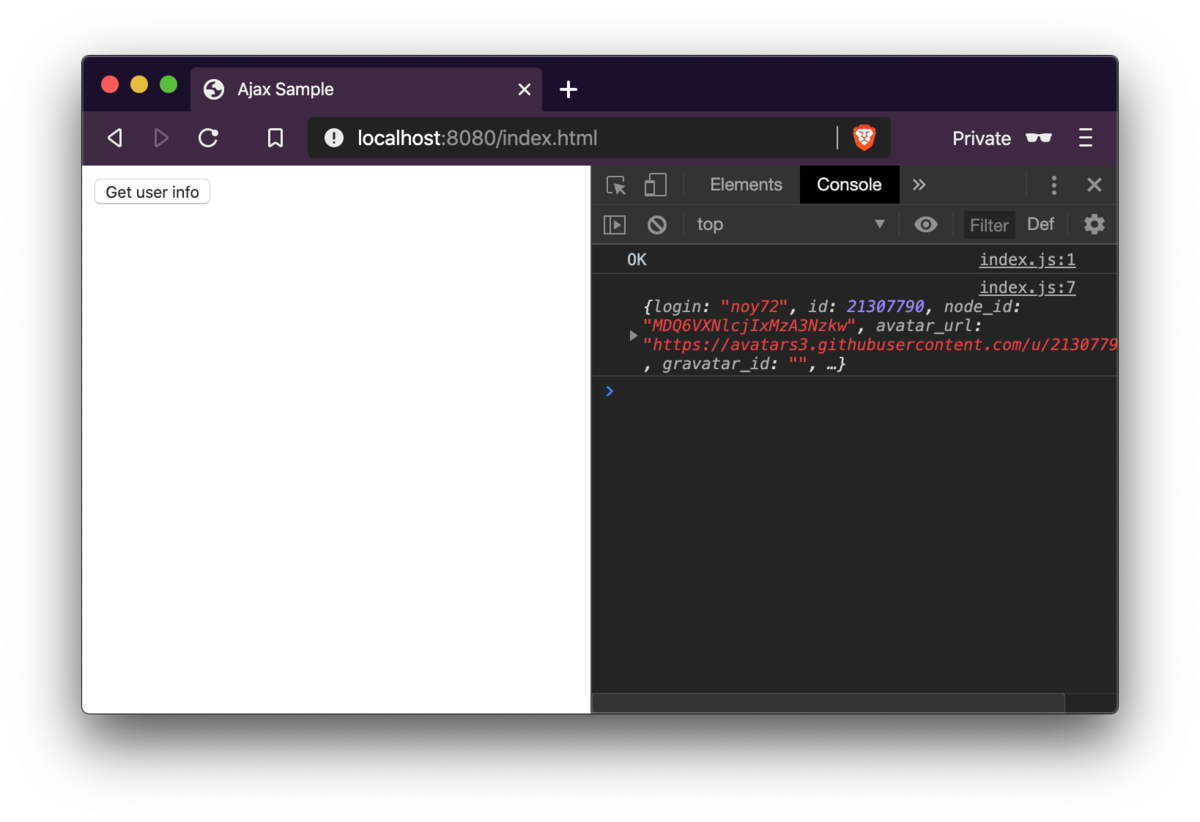
データをページに表示する
得られたデータをページに表示するようにします.
今回は,
- アバター
- ユーザー名
- ユーザーID
- フォロー数
- フォロワー数
- レポジトリ数
を表示表示します.
HTMLの組み立て
HTMLは以下のような構造にします.
.
├── ユーザー名,ユーザーID
├── アバター
└── .
├── フォロー数
├── フォロワー数
└──レポジトリ数
Element#innerHTMLプロパティに作成したHTML文字列をセットする方法がありますが,HTMLのエスケープ処理をしたくないので,今回はElementオブジェクトを生成してツリーを構築します.
結果を表示する部分の作成
button要素とscript要素の間に空のdiv要素を入れておきます.
... <button onclick="fetchUserInfo('noy72');">Get user info</button> <div></div> <!-- ここにユーザー情報を表示する --> <script src="index.js"></script> ...
HTMLの組み立てとDOMへの要素の追加
HTML要素はdocument.createElementで,単なる文字列はdocument.createTextNodeで作成します.Element#appendChildで子要素を追加してHTMLを組み立てます.
組み立てたHTMLは,用意しておいたdiv要素に挿入します.今回はquerySelectorでdiv要素を受け取り,そこに組み立てたHTMLを挿入します.
function buildHTML(info) { const user_name = document.createElement("h4"); user_name.appendChild( document.createTextNode(`${info.name} (@${info.login})`) ); const avatar = document.createElement("img"); avatar.src = info.avatar_url; avatar.alt = info.login; avatar.height = 100; const list = document.createElement("ul"); const following = document.createElement("li"); following.appendChild( document.createTextNode(`Following: ${info.following}`) ); const followers = document.createElement("li"); followers.appendChild( document.createTextNode(`Followers: ${info.followers}`) ); const repos = document.createElement("li"); repos.appendChild( document.createTextNode(`Repos: ${info.public_repos}`) ); list.appendChild(following); list.appendChild(followers); list.appendChild(repos); const result = document.querySelector('body > div'); result.appendChild(user_name); result.appendChild(avatar); result.appendChild(list); }
上記のコードは以下のようなHTMLを生成します(${}の部分は展開されます).
<div> <h4>${info.name} (@${info.login})</h4> <img src="${info.avater_url}" alt="${info.login}" height="100"> <ul> <li>Following: ${info.following}</li> <li>Followers: ${info.followers}</li> <li>Repos: ${info.public_repos}</li> </ul> </div>
buildHTMLを呼ぶ
fetchして得られたデータをbuildHTMLの引数にし,関数を呼びます.これで,ボタンを押すとデータが表示できるようになります.
if (response.ok) { response.json().then(userInfo => { buildHTML(userInfo); }); } else { ...

Asyncを使う
現在はfetchメソッドのコールバックでbuildHTMLメソッドを呼び,DOMに変更を加えています.
これを,Asyncを使って同期処理のように書き換えてみます.
main関数の追加
直接fetchUserInfoを呼ばずに,main関数を通して呼ぶようにします.
function main(){ fetchUserInfo("noy72") }
... <body> <button onclick="main();">Get user info</button> <div></div> ...
Promiseオブジェクトを返すようにする
fetchUserInfoでDOMを書き換えるのではなく,Promiseオブジェクトを返すようにします.成功した場合はResponse#jsonの戻り値をそのまま返し,失敗した場合はPromise.rejectでエラーを返します.
function fetchUserInfo(userId) { return fetch(`https://api.github.com/users/${encodeURIComponent(userId)}`).then( (response) => { if (response.ok) { return response.json(); } else { return Promise.reject( new Error(`${response.status} ${response.statusText}`) ); } } ); }
mainでPromiseを処理
fetchUserInfoはPromiseを返すようになったので,mainで処理します.成功した場合は(userInfo) => buildHTML(userInfo)が実行され,DOMを書き換えます.エラーが発生した場合は,(error) => console.log(error)が実行されます.
function main() { fetchUserInfo("noy72") .then((userInfo) => buildHTML(userInfo)) .catch((error) => console.log(error)) }
これでPromiseを使った処理ができるようになりました.コードは変わりましたが意味的にはPromiseを使っていないのと同じなので,前回実行した時と同様の動作をします.
Asyncを使う
Promiseを返すfetchUserInfoはawaitすることができます.
async function main() { try { const userInfo = await fetchUserInfo("noy72"); buildHTML(userInfo); } catch (error) { console.log(error); } }
fetchのコールバックで処理を行う実装から,手続的に処理を行う実装になりました.
作成したアプリのリポジトリ
JavaScript-Sample-Apps/Ajax-sample at master · noy72/JavaScript-Sample-Apps · GitHub
まとめ
GithubのAPIを呼び出し,取得したデータを表示するアプリを作成しました.
- サーバーを立てて,HTMLの表示とJavaScriptの実行をした
fetchを使ってHTTPリクエストを送った- DOMを書き換えて,APIから取得したデータを表示した
Async functionに置き換えた.
現在の実装ではユーザー名を埋め込んでいますが,Promiseを活用する · JavaScript Primer #jsprimerではユーザー名を変更できるように実装しています.
JavaScript勉強メモ [JavaScript Primer]
JavaScript Primerの第一章を読んで,知らなかった部分や重要な部分のメモ.
はじめに
JavaScript って何
JavaScript はウェブページ上に複雑なものを実装することを可能にするプログラミング言語です。
JavaScriptは主にウェブブラウザの中で動くプログラミング言語です。
Node.js って何
Node.js はスケーラブルなネットワークアプリケーションを構築するために設計された非同期型のイベント駆動の JavaScript 環境です。
(引用:Node.js とは | Node.js)
ECMAScript って何
JavaScriptの文法を定める仕様.ECMAScriptはどの実行環境でも共通な動作が定義されている.
ES2015は2015年にアップデートされたECMASCriptのこと.
strict mode って何
コードの先頭に "use strict";を書くと,実行モードがこれになる.
ある公文や機能が禁止される.
基本文法
変数
const
再代入不可.ただし,オブジェクトのプロパティなどは変更できるので,定数ではない.
const x = 5; x = 6; // TypeError: Assignment to constant variable. const obj = { value: 5 }; obj.value = 6;
let
再代入可.
var
あまり使わない方が良い.
- 再定義が可能
- 変数の巻き上げが起こる
var x = 6; var x = 7; // エラーは起きない console.log(hoge); // エラーは起きない.hoge = undefined var hoge = 5;
命名
キャメルケース
データ型
プリミティブ型
真偽値や数値などの基本的な値.イミュータブル.
Boolean
Number
String
undefined
null
Symbol
一意で不変な値のデータ型
オブジェクト
プリミティブ型の値やオブジェクトからなる集合.ミュータブル.
関数
引数
呼び出し時の引数が少ないと,undefinedが代入される.引数が多いと,その引数は無視される.
function add(a, b) { console.log(a, b); return a + b } console.log(add(2, 4)); // 2 4 // 6 console.log(add(2, 4, 7)); // 2 4 // 6 console.log(add(2)); // 2 undefined // NaN
Spread構文
配列の前に...をつけると,配列の値を展開したものが返される.
function add(a, b) { return a + b } const a = [2,4]; console.log(...a); // 2 4 console.log(add(...a)); // 6
arguments
関数に渡された引数の値が全て入ったArray-likeなオブジェクト
function add(a, b) { console.log(arguments); // [Arguments] { '0': 2, '1': 4, '2': 7, '3': 'foo' } return a + b } add(2, 4, 7, "foo");
オーバーロードはない
後から宣言した関数のみが有効.
function f(){ console.log(5); } function f(x){ console.log(x); } f(); // undefined f(6); // 6
分割代入
ブレースでオブジェクトのプロパティを取り出せる.引数だけでなく,変数宣言時にも使える.
function print({value}) { console.log(value); } const obj = { value: 555 }; print(obj); // 555 const { value } = obj; console.log(value); // 555
即時実行関数
匿名関数の宣言と実行をまとめて行うことで,グローバルスコープの汚染を避けられる.
(function() { console.log("foo"); })();
クロージャー
参照されている変数のデータが保持されるため,変数xはcounter()実行後も参照し続けられる.
const counter = () => { let x = 0; return function inc(){ return ++x; } }; const inc = counter(); console.log(inc()); // 1 console.log(inc()); // 2 console.log(inc()); // 3
オブジェクト
プロパティの存在確認
const obj = { value: 1, str: "foo" }; console.log("value" in obj); // true console.log("str" in obj); // true console.log("obj" in obj); // false
in演算子とhasOwnPropertyメソッドは同じ動作をするが,厳密には異なる.
const obj = {}; console.log("toString" in obj); // true console.log(obj.hasOwnProperty("toString")); // false
in:objには定義されていないが,プロトタイプオブジェクトには存在するため真
hasOwnProperty:obj自体に定義されていないため偽
配列
TypedArray
固定長,かつ型付きの配列.
const typedArray = new Int8Array(2); typedArray[0] = 127; typedArray[1] = 128; console.log(...typedArray); // 127 -128
配列の検索
findIndexはインデックスを返し,findは要素を返す.
const array = ["a", "bb", "ccc"]; console.log(array.findIndex(obj => obj === "bb")); // 1 console.log(array.find(obj => obj === "bb")); // bb
配列の操作
push_front : unshift
pop_front : shift
const array = ['foo']; array.push('push'); array.unshift('unshift'); console.log(array); // [ 'unshift', 'foo', 'push' ] console.log(array.pop()); // push console.log(array); // [ 'unshift', 'foo' ] console.log(array.shift()); // unshift console.log(array); // [ 'foo' ]
多次元配列を一次元配列にする
Array#flatを使う.パラメータで展開する深さを指定できる.全て展開する場合は,Infinityを用いる.
const array = [[[1], [2]], [3], 4]; console.log(array.flat(1)); // [ [ 1 ], [ 2 ], 3, 4 ] console.log(array.flat(Infinity)); // [ 1, 2, 3, 4 ]
配列のコピー
Array#concatやArray#sliceで配列をコピーすることができる.
function f_1(array) { const a = array.concat(); a[0] = "new"; return a; } function f_2(array) { const a = array.slice(); a[0] = "new"; return a; } function f_3(array) { const a = array; a[0] = "new"; return a; } { const array = [1, 2]; console.log(f_1(array)); // [ 'new', 2 ] console.log(array); // [ 1, 2 ] } { const array = [1, 2]; console.log(f_2(array)); // [ 'new', 2 ] console.log(array); // [ 1, 2 ] } { const array = [1, 2]; console.log(f_3(array)); // [ 'new', 2] console.log(array); // [ 'new', 2] }
文字列
タグ付きテンプレート関数
関数 テンプレート文字列と記述すると,${}で区切られた文字列と${}の評価結果を引数にして関数を呼ぶ.
function f(strings, ...values) { console.log(strings); console.log(values); } f(["aa", "bb", "cc"], 1, 2); // 普通の関数呼び出し // [ 'aa', 'bb', 'cc' ] // [ 1, 2 ] f`aa${1}bb${2}cc`; // テンプレート文字列を使った関数呼び出し // [ 'aa', 'bb', 'cc' ] // [ 1, 2 ]
クラス
コンストラクタはクラス名ではなくconstructorで定義する.必須.
class MyClass { constructor() { console.log("constructor") } } const myClass = new MyClass(); // constructor
また,クラスを値として定義できる.
const c = class MyClass { constructor() { console.log("constructor") } }
メソッドの定義
functionと書かずに関数名(パラメータ)と書く.このメソッドはプロトタイプメソッドと呼び,インスタンス間で共有される.
class MyClass { constructor() { this.value = 0; } inc() { this.value++; } } const myClass = new MyClass(); console.log(myClass.value); // 0 myClass.inc(); console.log(myClass.value); // 1
以下のようにthisに対してメソッドを定義すると,インスタンス間で共有されない.
this.inc = () => { this.value++; }
アクセッサプロパティ
メソッドの頭にgetやsetをつけると,プロパティへの参照や代入時に呼び出されるメソッドが定義できる.
アクセッサプロパティを用いると,プロパティに対する参照,代入をしたときに何らかの処理を行える.
class MyClass { constructor() { this.value = 0; } get a(){ return this.value; } set b(value){ this.value = value; } } const myClass = new MyClass(); console.log(myClass.a); // 0 console.log(myClass.b = 3); // 3 console.log(myClass.a); // 3
非同期処理
どのスレッドで実行されるか
class Timer { constructor() { this.start = Date.now(); } // Timerインスタンスを生成してから経過した時間を表示する. log(message) { console.log( String(Date.now() - this.start) + " ms : " + message ); } } // tミリ秒コードの実行を止める. function block(t) { const start = Date.now(); while (true) { const diff = Date.now() - start; if (diff > t) { return; } } } const timer = new Timer(); timer.log("Begin"); setTimeout(() => { timer.log("Begin_setTimeout"); block(1000); timer.log("End_setTimeout"); }, 3000 ); timer.log("End");
このコードの実行結果は以下のようになる.
0 ms : Start 6 ms : End 3012 ms : Start_setTimeout 4013 ms : End_setTimeout
メインスレッドのtimer.log("Start")とtimer.log("End")が順に実行され,その約3秒後にsetTimeout内の関数が呼ばれる.この動作から,setTimeout内の関数とメインスレッドは独立して動いているように見える.
次に,以下のようにblock()を増やしてみる.
const timer = new Timer(); timer.log("Start"); setTimeout(() => { timer.log("Start_setTimeout"); block(1000); timer.log("End_setTimeout"); }, 3000 ); block(5000); timer.log("End");
このコードの実行結果は以下のようになる.
0 ms : Start 5007 ms : End 5008 ms : Start_setTimeout 6009 ms : End_setTimeout
- 実行
- 実行してから3秒後に
setTimeout内の関数実行 - 実行してから5秒後に
timer.log("End")を実行
とはならない.
- 実行
- 実行してから3秒後に
setTimeout内の関数を実行しようとするが,block(5000)の実行が終わっていないので実行されない. - 実行してから5秒後に
timer.log("End")を実行 setTImeout内の関数を実行
となる.setTimeoutでの関数実行はメインスレッドで行われるため,メインスレッドをblock()で止めると,その分実行が遅れる.
Promise
非同期処理の結果を表現するオブジェクト.
const promise = new Promise(関数 foo); promise.then(fooの実行に成功したときに呼ぶ関数,fooの実行に失敗したときに呼ぶ関数)
resolveとrejectの2つの引数を取る関数をPromiseに与える.与えた関数の実行が成功ならresolveを呼び,失敗ならrejectを呼ぶ.
function foo(resolve, reject) { resolve(123); } function success(value) { console.log("resolve", value); } function failure(value) { console.log("reject", value * 2); } const promise = new Promise(foo); promise.then(success, failure); // resolve 123 // 匿名関数を使った場合 const promise = new Promise((resolve, reject) => { resolve(123); } ).then( (value) => { console.log("resolve", value); }, (value) => { console.log("reject", value * 2); } ); // resolve 123
例外が起こった場合はrejectを呼ぶ.
const promise = new Promise((resolve, reject) => { throw new Error("hogehoge"); } ).then( (value) => { console.log("resolve", value); }, (value) => { console.log("reject!!", value); } ); // reject!! Error: hogehoge // (省略)
Promiseチェーン
thenはPromiseオブジェクトを返すので,.then().then()...と繋げることができる.
const timer = new Timer(); const promise = new Promise((resolve, reject) => { timer.log("1. 何らかの処理を実行"); block(1000); resolve(); } ).then( () => { timer.log("2. 処理が成功") } ).then( () => { timer.log("3. 別の処理を実行"); block(2000); timer.log("4. 処理が終了") } );
1 ms : 1. 何らかの処理を実行 1007 ms : 2. 処理が成功 1007 ms : 3. 別の処理を実行 3008 ms : 4. 処理が終了
複数のPromiseをまとめる
Promise.all(Promiseのリスト)と書く.
const timer = new Timer(); function getPromise(ms) { return new Promise((resolve) => { timer.log(`${ms}ミリ秒待機`); setTimeout(() => { resolve(ms); }, ms); }) } const p1 = getPromise(1000); const p2 = getPromise(2000); const p3 = getPromise(3000); Promise.all([p1, p2, p3]).then((values) => { timer.log("Promise.all"); console.log(values); } );
1 ms : 1000ミリ秒待機 9 ms : 2000ミリ秒待機 9 ms : 3000ミリ秒待機 3014 ms : Promise.all [ 1000, 2000, 3000 ]
Promiseが1つでも失敗すると,Promise.allは失敗時の処理を呼び出す.
Promiseが1つでも成功したときにコールバック関数を呼ぶときはPromise.raceを使う.
Async Function
非同期処理を同期処理として書きたくなったり,thenで無限にチェーンが繋がっていくのが辛くなったときに使える構文.
async functionと記述すると,その関数はPromiseを返す.
async function f() { return 123456; } f().then(value => { console.log(value); // 123456 });
この場合だと,f()はPromise.resolve(123456);を返す.
async functionはawaitを使って実行が終わるまで待つことができる.
const timer = new Timer(); async function f() { timer.log("Begin async function f"); return new Promise((resolve, reject) => { setTimeout(() => resolve(123456), 1000) }); } async function g(){ const a = await f(); timer.log("End async function f"); const b = await f(); timer.log("End async function f"); console.log(a, b); } g();
await f()で約1秒間,止まっているのがわかる.
0 ms : Begin async function f 1009 ms : End async function f 1010 ms : Begin async function f 2015 ms : End async function f 123456 123456
awaitを削除するとどうなるか.
async function g(){ const a = f(); timer.log("End async function f"); const b = f(); timer.log("End async function f"); console.log(a, b); }
0 ms : Begin async function f
5 ms : End async function f
5 ms : Begin async function f
5 ms : End async function f
Promise { <pending> } Promise { <pending> }
1秒もかからずにメインスレッドが終了する.async functionであるf()はPromiseを返すだけである.
感想
JavaScript PrimerはJS初心者にかなりおすすめ.説明が丁寧でわかりやすく,関連した情報も併せて書いてあるので,単に文法を調べる以上の情報が得られる.また,サンプルコードをサイト上で実行できるので,コードをいじることも簡単にできる.
非同期処理が全くわかっていなかったので,https://jsprimer.net/basic/async/:tilte は特に勉強になった.よく見るコールバックを用いたコードから,Promise,Async Functionを段階を踏んで説明してくれるので,とてもわかりやすかった.
簡単なプログラムだけど,非同期処理の関数をPromiseで包んで,awaitを使って同期処理っぽく書くことができるようになって満足.